WSLおよびUbuntuPCにlinuxbrewをインストール
初めに
NGS解析は、この本を主に参考にしてやろうと思っています。
以前この本の第一版をボスに買ってもらって練習してたんですが、
と挫折して、結局ネットの知識でUbuntuPCを使ってやりはじめて、ほとんど読みませんでした。
この間調べたら2019年12月に第二版が出たらしかったので、さっそく書店で購入して今手元にあります。
これの最初にはHomebrewを入れろと書いてあります。
Homebrewはmac用のソフトウェアで、Homeディレクトリにroot権限無しでソフトウェアをインストールできるパッケージマネージャーです。
HomebrewがLinuxやWSLに対応したいわゆる「Linuxbrew」がありますので、こちらをインストールします。
インストールする先は、解析用に組んであるUbuntuPCと、自前のWindowsPC内のWSLです。
やったこと
参考にしたのはこちらの記事です。
以下のコマンドで入りました。
# 事前準備 $ sudo apt-get install build-essential curl file git # インストール $ sh -c "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install.sh)" # linuxbrewにPATHを通す $ test -d ~/.linuxbrew && eval $(~/.linuxbrew/bin/brew shellenv) $ test -d /home/linuxbrew/.linuxbrew && eval $(/home/linuxbrew/.linuxbrew/bin/brew shellenv) # .profileに先ほどのPATH追加コードを書き込んで自動化しておく $ echo "eval $($(brew --prefix)/bin/brew shellenv)" >>~/.profile
brew install sl sl
以上。書き写しになってすみません。ubuntuPCとWSL両方でいけました。
次はMACS2を入れてchip解析をしてみます。
雑談
そういえばこのブログ、まだボスに許可取ってないんだけど、こういうのって許可取ったほうがいいんですかねえ?
一応書き散らすだけならSNSと変わらないし自由じゃないかなとは思うんですが、元は後輩に「このブログ読め」って言って指導を楽にすることが目的の一つなので、一応一言言っておくかな?
参考文献
WindowsのWSLでNGS解析するための準備3 ~VSCodeでWSLを使う~
初めに
WSLでNGS解析をするための準備をいくつか記事にしています。
WSLを使うときはWSLアプリ(=コマンドプロンプト?)でいじる必要があったのですが、以下のサイトにVSCodeで操作できるようになったと書いてあったので、試してみます。
イメージ的にはこんな感じ?

やったこと
VSCodeを開いて、「Remote - WSL」をインストール。
そしてWSLを開いて、
code .
を実行。色々インストールが開始します。
左下に

こういう表示が出ればOKらしいです。
ターミナルを表示させるとこんな感じ。

これは便利!!!
WSLのリモート接続をやめたいときは、「ファイル>リモート接続を閉じる」でやめれます。
また、リモート接続を開始したいときは、左下の緑のリモートマークをクリックして、Remote-WSL: New Windowを選べば接続が開始されます(F1キー>Remote-WSL: New Windowでもいけるっぽいです)。

まとめ
まじで、これでNGS解析余裕では?
参考資料
WSLでNGS解析の記事リスト
pythonであるフォルダ内のファイル名を参照して別のフォルダ内のファイルをリネーム
初めに
以前にpythonでファイル名を自動で書き直してくれるコードを書きました。
これを改変して、あるフォルダにあるファイルの名前をリスト化して、他のフォルダにあるファイル名をリスト通りに変更するコードを作りました。

こんな感じ。
変更する側のフォルダ内のファイルは、前回と同様"画像_0001.tif"みたいにolympusの顕微鏡の出力を前提としています。
ファイル内のコメントでも書いてますが、10は1と2の間に数えられるので、変更元のフォルダ内のファイル名が数字で始まっていて、且つ10以上である場合は注意が必要です*1。
結果
#! python3 # rename same folder.py - あるフォルダ内のファイル名を他のフォルダ内のファイル名にするため、forループを用いてrenameする # 10は1と2の間に数えられるので、区画が10以上ある場合は注意 from tkinter import Tk, messagebox, filedialog import os import glob import re import shutil # ファイル選択ダイアログの表示 root = Tk() root.title(u"変更するフォルダーの選択") root.withdraw() iDir = os.path.abspath(os.path.dirname(__file__)) messagebox.showinfo("○×プログラム", "変更するフォルダーを選択してください") cfolder = filedialog.askdirectory(initialdir=iDir) root = Tk() root.title(u"元となるフォルダーの選択") root.withdraw() messagebox.showinfo("○×プログラム", "元となるフォルダーを選択してください") rfolder = filedialog.askdirectory(initialdir=cfolder) # ファイルのリストを取り込む cfilelist = [] for f in glob.glob(cfolder + "/画像_*.tif"): cfilelist.append(os.path.split(f)[1]) rfilelist = [] for g in glob.glob(rfolder + "/*.tif"): rfilelist.append(os.path.split(g)[1]) # リネーム作業 k = 0 while k < len(cfilelist): shutil.move(cfolder + "/" + cfilelist[k], cfolder + "/" + rfilelist[k]) k += 1
まとめ
tkinterは便利ですね。
これで面倒くさい作業は大概自動化できたかな?
追記 (2020/10/26)
10以上の数にも対応できるようにしました。
ファイル名が「'/d+'. 」の正規表現で引っかかってくるものであればこれでできます。(例:「24. HEK293T d4 EGFP-OE.tif」)
#! python3 # rename same folder more than 10.py - あるフォルダ内のファイル名を他のフォルダ内のファイル名にするため、forループを用いてrenameする from tkinter import Tk, messagebox, filedialog import os import glob import re import shutil # ファイル選択ダイアログの表示 root = Tk() root.title(u"変更するフォルダーの選択") root.withdraw() #iDir = os.path.abspath(os.path.dirname(__file__)) iDir = "C:/Users/shinn/OneDrive - Kyoto University/南研/data" messagebox.showinfo("○×プログラム", "変更するフォルダーを選択してください") cfolder = filedialog.askdirectory(initialdir=iDir) root = Tk() root.title(u"元となるフォルダーの選択") root.withdraw() messagebox.showinfo("○×プログラム", "元となるフォルダーを選択してください") rfolder = filedialog.askdirectory(initialdir=cfolder) # ファイルのリストを取り込む cfilelist = [] for f in glob.glob(cfolder + "/画像_*.tif"): cfilelist.append(os.path.split(f)[1]) rfilelist = [] for g in glob.glob(rfolder + "/*.tif"): rfilelist.append(os.path.split(g)[1]) # 10以上あるときのsearchにおいて、数値無しを0とする関数 def extract_num(s, p, ret=0): search = p.search(s) if search: return int(search.groups()[0]) else: return ret # 10以上あるときのリストの並べ替え p = re.compile(r'(\d+). (.+).tif') rfilelist_sorted = sorted(rfilelist, key=lambda s: extract_num(s, p)) # リネーム作業 k = 0 while k < len(cfilelist): shutil.move(cfolder + "/" + cfilelist[k], cfolder + "/" + rfilelist_sorted[k]) k += 1
参考文献
*1:一応1-9の後に10を配置する方法もあるらしいですが、面倒くさいので採用してません。note.nkmk.me
linuxで作業ログを取る
初めに
解析用のPCはlinux(ubuntu)なのですが、以前OSをアップデートする際に誤ってクリーンインストールしてしまったので、頑張って作った設定がすべて消えてしまいました。。。
再設定をしていく過程で、記事になりそうなことがあれば、このブログに追記していこうと思います。
目的
解析を開始するときにターミナルから入力していくのですが、この作業をtextファイルで記録することができれば、いつでも見直すことができるため再現性の担保につながります。
今回は、ターミナルの入力および出力をtextファイルで記録する方法について書いていきます*1。
内容
設定するところは二カ所です。
まずターミナルを起動し、
$ nano .bashrc
と打ち込みます*2。
nanoはeditorと呼ばれ、ターミナル上でファイル内容を編集することのできるコマンドです。
すると、ターミナルの表示が変わり、.bashrcファイルの中身が表示されると思います。

最終行に
# start alias alias start="bash /home/*****/local/setting/alias/start.sh"
と記述し、Ctrl+Oで書き込み、Ctrl+Xで終了します。
間違えて.bashrcファイルをいじってしまった場合は、書き込みせずにCtrl+Xで終了してください。
設定ファイルをいじってしまうとめんどくさいので。
aliasコマンドは、新しく好きなコマンドを設定できるコマンドです(今回は"start"というコマンドを作っています)。
*****は自分のusernameを入れてください。ちなみに、.shファイルへのPATHは自分の好きなものにしていただいて構いません。
次に、
mkdir -p ~/local/setting/alias #aliasの.shファイル保存用ディレクトリ作成 mkdir ~/local/log #log保存用ディレクトリ作成 nano ~/local/setting/alias/start.sh
と打ち込み、start.shファイルを指定の場所に作成します。
何も書いていないファイルが開かれますので、
#!/bin/sh
# for make log file
today=$(date "+%Y%m%d-%H%M")
folder=$(basename `pwd`)
echo "Hello! Welcome to ***** PC (・v・)/"
echo "what is your name?"
read name
logfilename=${today}-${name}-${folder}
script /home/*****/local/log/${logfilename}.txt
と記入し、同様に保存します。
このように、.shファイルの中に自分の行いたいコードを記載し、.shファイルを実行することで一度にすべてのコードを実行することをシェルスクリプトといいます。
ターミナルを再起動して、ターミナル上に
start
と入力すると、
Hello! Welcome to ***** PC (・v・)/ what is your name? wet-to-dry #ここは自分で入力する スクリプトを開始しました。ファイルは /home/*****/local/log/20200929-1828-wet-to-dry-*****.txt です
という感じでログの記録が開始します。
ログは "/home//local/log/20200929-1828-wet-to-dry-.txt"にテキストファイルで保存されています。

ログの記録をやめたいときは
exit
と一回入力すれば良いです*3。
ログの見方
ログを見るときは
cat /home/*****/local/log/20200929-1828-wet-to-dry-*****.txt
とcatを使ってください。
script関数はcolorcodeが出力に入ってしまっているため、viやnano、text editorなどで見ようとするととても読みづらいです。
cat↓
Script started on 2020-09-29 18:45:06+0900 *****@*****:~$ exit exit Script done on 2020-09-29 18:46:03+0900
nano↓
Script started on 2020-09-29 18:45:06+0900 ^[]0;*****@*****: ~^G^[[01;32m*****@*****^[[00m:^[[01;34m~$ exit Script done on 2020-09-29 18:46:03+0900
まとめ
まあ、基本的に解析したら入出力すべて実験ノートにすべきで、実験ノートに書いておけばログ機能はいらないとは思います。
過去の実験ノートをOnenoteで電子化した記事も貼っときます
Rを用いたrealtime PCRの統計解析
初めに
前回の記事でRの開発環境について、いくつか書きました。
やっとこさ統計解析の本題に入っていきます。Realtime PCRのデータの統計解析です。
t検定だけならばExcelの関数や手計算で何とかいけていたのですが、ANOVAとTukey-Kramer法を使わなければならなくなったので、Rを使って検定していきます。
Tukey-Kramer法やその他の多重検定についてはこのサイトやこのサイトがわかりやすかったです。
試行錯誤
元データはExcelで持っているので、何とかしてExcelからデータを入力したい。
このサイトを見たところ、
csvで書きだしてから処理
コピペしてclipboardから読み込む
Rパッケージを使う
があるらしいですね。
csvファイルが増えると管理が面倒になるので、できるだけ余分なファイルを作らずにやりたいところ。
一番シンプルでスマートなのはRパッケージかな、と思いましたので、一番有名っぽい"readxl"パッケージをinstallしてみます。
>install.packages("openxl") WARNING: Rtools is required to build R packages but is not currently installed. Please download and install the appropriate version of Rtools before proceeding: https://cran.rstudio.com/bin/windows/Rtools/ Warning in install.packages : 'lib = "C:/Program Files/R/R-4.0.2/library"' is not writable Warning in install.packages : ディレクトリ 'C:\Users\*******' を作成できません、理由は 'Invalid argument' です Error in install.packages : unable to create ‘C:/Users/********/R/win-library/4.0’ >
いくつかポップアップダイアログが出た後、このようにエラーで止まってしまいます。
これはこのサイトから、管理者としてRStudioを実行すればいけました。
次に詰まったのが、
> library(readxl) > xl = readxl::read_excel("C:\Users\excelへのPATH\*****.xlsx", sheet = 1) エラー: ""C:\U" で始まる文字列の中で 8 進文字なしに '\U' が使われています >
と、readxlパッケージがPATHを読んでくれません。これはこのサイトから、PATH中のバックスラッシュをスラッシュにしなければならないらしく、
> library(readxl) > xl = readxl::read_excel("C:/Users/excelへのPATH/*****.xlsx", sheet = 1) New names: * `` -> ...4 * AVERAGE -> AVERAGE...8 * SE -> SE...9 * `` -> ...10 * `` -> ...12 * ... > xl # A tibble: 54 x 21 `Sample Name` `Target Name` `Cт Mean` ΔCT ref RQ AVERAGE...7 SE...8 ...9 <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl> 1 A-1 Gapdh 29.8 0 0 1 1 0 NA 2 A-1 Aaa 26.6 -3.21 -3.03 1.13 1. 0.111 NA 3 A-1 Bbb 26.8 -2.92 -2.55 1.29 1 0.152 NA 4 A-1 Ccc 27.5 -2.28 -1.92 1.28 1. 0.176 NA 5 A-1 Ddd 27.3 -2.44 -1.92 1.44 1.00 0.220 NA 6 A-1 Eee 26.6 -3.19 -2.79 1.32 1 0.169 NA 7 A-2 Gapdh 29.2 0 NA 1 NA NA NA 8 A-2 Aaa 26.5 -2.67 NA 0.779 NA NA NA 9 A-2 Bbb 27.0 -2.20 NA 0.785 NA NA NA 10 A-2 Ccc 27.8 -1.36 NA 0.679 NA NA NA # ... with 44 more rows, and 12 more variables: コピー <dbl>, ...11 <dbl>, # ...12 <dbl>, t検定 <dbl>, ...14 <chr>, AVERAGE...15 <dbl>, ...16 <dbl>, # ...17 <dbl>, ...18 <lgl>, SE...19 <dbl>, ...20 <dbl>, ...21 <dbl> > >
とスラッシュにすればいけました。また、"\"のようなダブルバックスラッシュでもいけました。エスケープ文字だと認識してしまうのかな?
このデータを使って、検定していきます。
ちなみに、データの構造はこの図のようになっています。

一応、僕の使っているデータも置いておくので、練習にでも使ってください。
僕はrealtime PCRの解析においてΔCT値を正規分布していると考えて検定しますので(参考)、まず"サンプル名"、"遺伝子名"、"ΔCT値"の列を抜き出します。
列の抽出の参考はこちら。
> columnList = c("Sample Name", "Target Name", "ΔCT") #make columnList > data = xl[, columnList] #access data > data[1,1] # A tibble: 1 x 1 `Sample Name` <chr> 1 A-1 >
そして、次に遺伝子名リストを作成し、それぞれの行を抽出します(データ検索の参考、列抽出の参考)。
> geneList = c("Aaa", "Bbb", "Ccc", "Ddd", "Eee") > gene1 = data[data$"Target Name"=="Aaa",] > vx = gene1$ΔCT > vx #遺伝子名"Aaa"の行が抽出されてベクトルで表示されるはず [1] -3.21 -2.67 -3.15 -2.79 -2.50 -2.61 -2.83 -2.53 -3.16 >
このデータを使ってTukey-Kramer法で検定を行います。Rを用いたTukey-Kramer法についてはこちらのサイトを参考にしました。
> fx = factor(rep(c("A","B","C"),c(3,3,3))) > TukeyHSD(aov(vx~fx)) Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = vx ~ fx) $fx diff lwr upr p adj B-A 0.3766667 -0.2835209 1.0368542 0.2633039 C-A 0.1700000 -0.4901875 0.8301875 0.7222893 C-B -0.2066667 -0.8668542 0.4535209 0.6256951 >
これを、それぞれの遺伝子で再帰的に解析します。この際、変数(gene1~gene5)を再帰的に作成する必要があったので、このサイトを参考にしました。
> for (i in 1:length(geneList)) { + gene = data[data$"Target Name"==geneList[i],] + vx = gene$ΔCT + fx = factor(rep(c("A","B","C"),c(3,3,3))) + assign(paste("gene", i, sep = ""), TukeyHSD(aov(vx~fx))) + } > gene5 Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = vx ~ fx) $fx diff lwr upr p adj B-A 3.323333 1.69604402 4.95062264 0.0018627 C-A 1.666667 0.03937736 3.29395598 0.0456456 C-B -1.656667 -3.28395598 -0.02937736 0.0467114 >
何とかできました。
最後に、データをtxtファイルで出力するコードを書きます。普通に出力してもよかったのですが、Tukey-Kramerの出力がlist形式でわかりづらかったのと、行列の縦がそろったまま見やすく出力したかったので、sink()という関数を使いました。sink()の参考はこちら。
> fileName = "Tukey-Kramer-result.txt" > path = paste(getwd(), fileName, sep="/") > sink(path, append = T) > fileName > for (i in 1:length(geneList)){ + print(geneList[i]) + print(get(paste("gene", i, sep = ""))) + } > sink() >
sink()はコマンドラインに結果が出る代わりに指定したファイルに結果を保存してくれる関数です。
これで結果まで保存できるようになりました。
結果
以上をまとめたものがこちら。
####200922 test3.R#### #変更必要 #install.packages("readxl") library(readxl) #データを読み込み xl = readxl::read_excel("C:/Users/*****/200922 test3.xlsx", sheet = 1) #変更必要 columnList = c("Sample Name", "Target Name", "ΔCT") data = xl[, columnList] #遺伝子リストを作成 geneList = c("Aaa", "Bbb", "Ccc", "Ddd", "Eee") #変更必要 #再帰的に解析 for (i in 1:length(geneList)) { gene = data[data$"Target Name"==geneList[i],] vx = gene$ΔCT fx = factor(rep(c("A","B","C"),c(3,3,3))) #変更必要 assign(paste("gene", i, sep = ""), TukeyHSD(aov(vx~fx))) } #以降は記録用 fileName = "Tukey-Kramer-result.txt" path = paste(getwd(), fileName, sep="/") sink(path, append = T) fileName for (i in 1:length(geneList)){ print(geneList[i]) print(get(paste("gene", i, sep = ""))) } sink()
その都度変更しなければならないところは#変更必要と書いてあります。
これの出力はこちら
[1] "Tukey-Kramer-result.txt" [1] "Aaa" Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = vx ~ fx) $fx diff lwr upr p adj B-A 0.3766667 -0.2835209 1.0368542 0.2633039 C-A 0.1700000 -0.4901875 0.8301875 0.7222893 C-B -0.2066667 -0.8668542 0.4535209 0.6256951 [1] "Bbb" Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = vx ~ fx) $fx diff lwr upr p adj B-A 3.066667 1.6294337 4.5038996 0.0014778 C-A 1.953333 0.5161004 3.3905663 0.0138771 C-B -1.113333 -2.5505663 0.3238996 0.1194498 [1] "Ccc" Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = vx ~ fx) $fx diff lwr upr p adj B-A 2.736667 0.7334353 4.7398980 0.0135548 C-A 1.416667 -0.5865647 3.4198980 0.1555501 C-B -1.320000 -3.3232314 0.6832314 0.1877137 [1] "Ddd" Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = vx ~ fx) $fx diff lwr upr p adj B-A 3.470000 1.6473849 5.2926151 0.0026843 C-A 2.173333 0.3507183 3.9959484 0.0246693 C-B -1.296667 -3.1192817 0.5259484 0.1529928 [1] "Eee" Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = vx ~ fx) $fx diff lwr upr p adj B-A 3.323333 1.69604402 4.95062264 0.0018627 C-A 1.666667 0.03937736 3.29395598 0.0456456 C-B -1.656667 -3.28395598 -0.02937736 0.0467114
BbbのA-B, A-C
CccのA-B
DddのA-B, A-C
EeeのA-B, A-C, B-C
でp<0.05の有意差ありとなっていますね。
まあ、予想通りの結果でした。
まとめ
いい感じでできたので満足です。これを応用すれば他の多重検定も簡単にできると思います。
参考
www.slideshare.net
RStudioでGitを使う
初めに
前回の記事で、RStudioでRを開発することにしました。
RStudioではGitでversion管理を行えるらしいので、Gitを入れてみます。
Gitを入れる
Gitのページからダウンロードします。
ほぼこのブログを参考にGit for Windowsを入れました。
ブログと違うところは、
Choosing the default editor used by GitをUse Visual Studio Code as Git's default editorにしたこと
Choosing HTTPS transport backendをUse the native Windows Secure Channel libraryにしたこと
Configuring the line ending conversionsをCheckout Windows-style, commit Unix-style line endingにしたこと
くらいです。
プロンプトで行った設定↓
$ git --version git version 2.28.0.windows.1 $ git config --global user.name "wet-to-dry" $ git config --global user.email "*****@*****.com" $ git config --list diff.astextplain.textconv=astextplain filter.lfs.clean=git-lfs clean -- %f filter.lfs.smudge=git-lfs smudge -- %f filter.lfs.process=git-lfs filter-process filter.lfs.required=true http.sslbackend=schannel core.autocrlf=true core.fscache=true core.symlinks=true pull.rebase=false credential.helper=manager core.editor="C:\Users\*****\AppData\Local\Programs\Microsoft VS Code\Code.exe" --wait user.name=wet-to-dry user.email=*****@*****.com
RStudioでGitを使う
今度はこのブログを参考に進めていきます。
まず、File>New Projectから新しいプロジェクトを作成しますが、図の「Create a git repository」にチェックを入れておきます。

すると、右上にGitのタブができます。
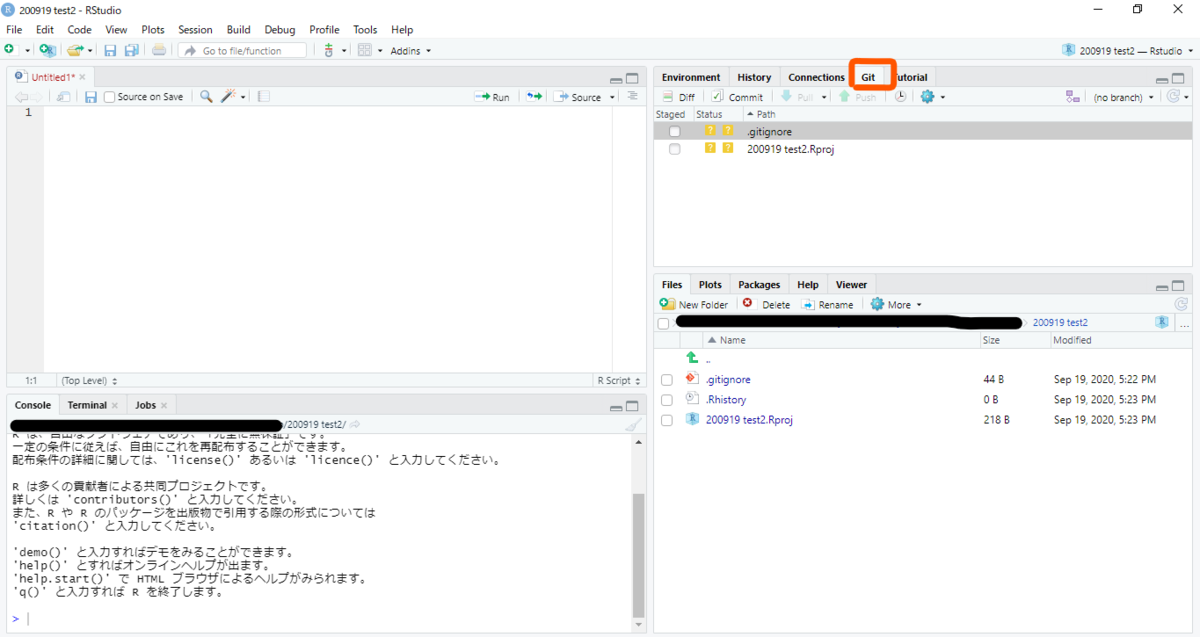
Gitペイン内のDiffボタンを押すと、commit用のウインドウが出てきます。
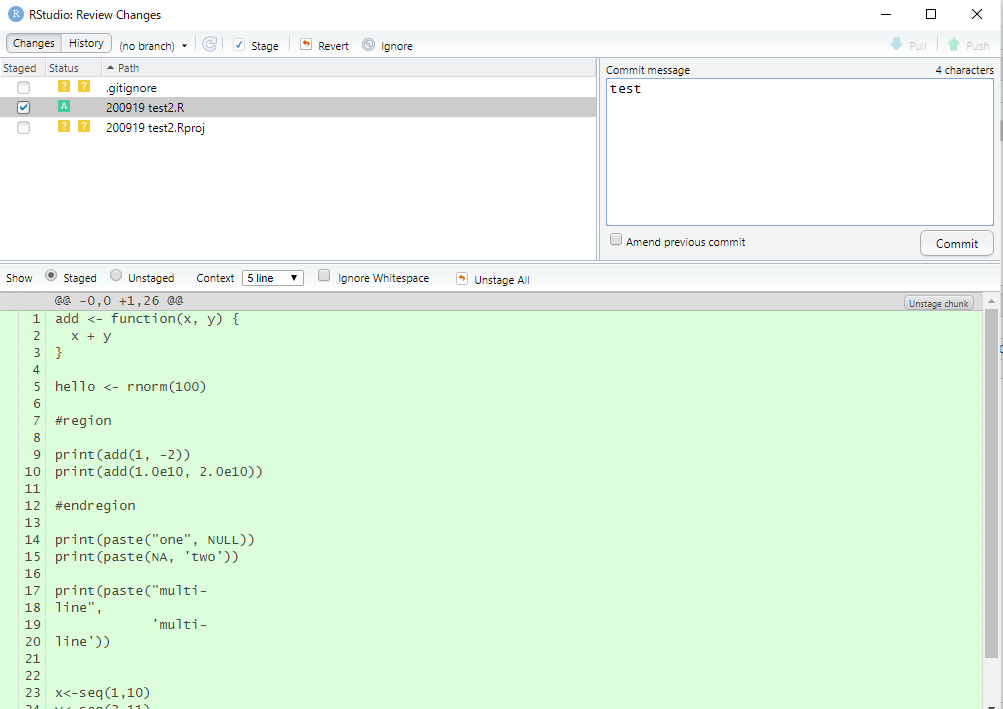
差分のcommitバージョン。

ちなみに、Status内のマークは
?→gitの管理対象になっていない
A(Added)→新たにgitの管理対象になった
D(Delete)→リポジトリにあったファイルが削除された
M(Modified)→リポジトリの状態から変更されている
U→リポジトリ間で差分が衝突している
らしいです。
また、フォルダ内に.gitignoreというファイルが作られますが、これはgitの管理対象にしないファイル(Gitペインに表示されないファイル)のリストらしいです。これを編集すれば管理対象にしないファイルを指定できるらしい。
GitHubと連携
引き続きこのブログを参考に進めていきます。
今までの処理はすべてローカルで保存されているだけらしい。
なので、GitHubなどのリモートレポジトリに入れられるようにする。
Rstudio用の新しいレポジトリを作成し、"https://github.com/ユーザー名/レポジトリ名.git"をコピー。

RstudioのGitペイン上で、歯車のボタンからShell...をクリック
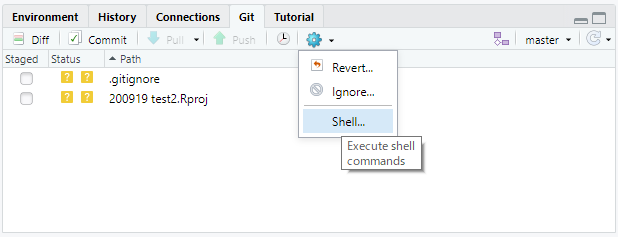
出てきたWindows Power Shellに
git remote add origin https://github.com/ユーザー名/レポジトリ名.git
を打ち込みます。
その後、branchボタンから
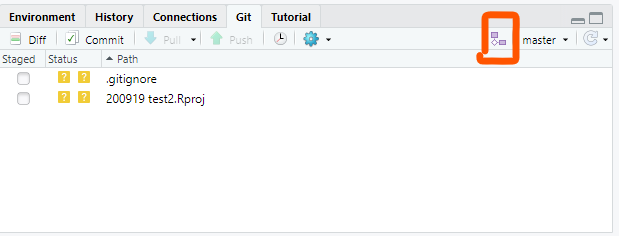
新しいbranchを作成し(Remoteはoriginでいいです)、Create!
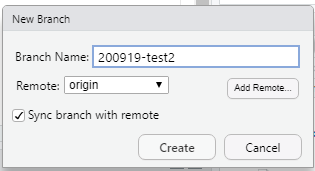
こんな感じで新しいbranchができます。
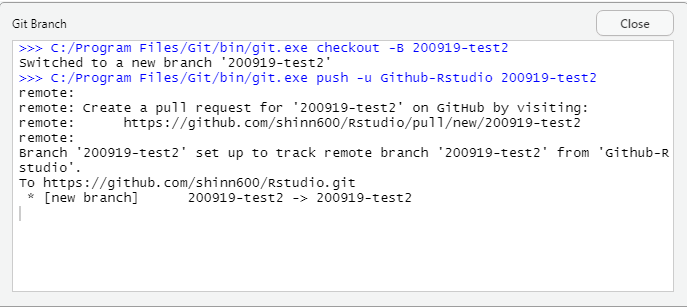
変更点がcommitし終わったら、pushボタンでリモートレポジトリを変更!
感想
とりあえずうまく行ったので一安心。